In chemoinformatics, comparing molecules to understand how similar they are is useful in many situations. Imagine you plan to synthesize a new organic compound without knowing how it might behave would it have certain biological activities? A quick similarity search can show you compounds with similar properties or activities, even if they do not share an exact substructure. Another example is screening a large library of tens of thousands of compounds. Instead of testing every molecule, it is often more efficient to select one representative compound from each group of relatively similar compounds, reducing redundancy and saving time and resources.
This is where chemical similarity searches and clustering demonstrate their value. Chemical similarity is based on the principle that molecules with similar structures tend to exhibit similar properties and biological activities. By quantifying similarity, researchers can identify compounds likely to behave in comparable ways, even without experimental testing. This approach is fundamental in many chemoinformatics applications, including virtual screening, lead optimization, and chemical space exploration.
Molecular Fingerprints
To compare molecules, we need a numerical representation of their structure. One common approach is using molecular Fingerprints. A fingerprint encodes the presence or absence of specific structural features, functional groups, or substructures in a molecule. Fingerprints can be binary, where each bit indicates the presence (1) or absence (0) of a feature, or count-based, where the frequency of each feature is recorded. Look at the following example:
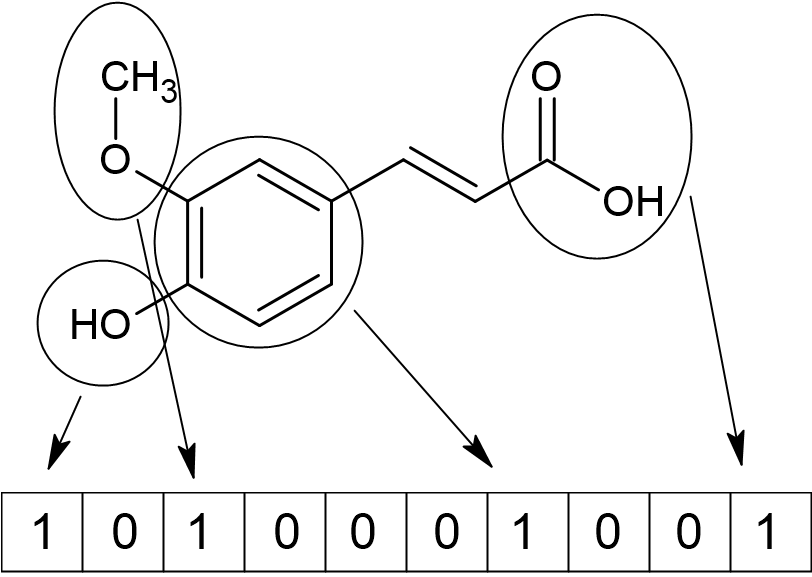
This image shows the compound ferulic acid. The binary fingerprint represents the presence or absence of specific structural features or substructures in the molecule. In this hypothetical fingerprint, there are 10 bits, where 1 indicates the presence of a feature and 0 indicates its absence. For ferulic acid, this fingerprint detects features such as an aromatic ring, a free hydroxyl group, an ether, and a carboxylic acid. The bits assigned 0 correspond to features absent from the molecule (such as a pyridine ring, a positive charge, or a cyano group).
Some widely used fingerprints include:
- MACCS keys: A set of 166 predefined structural features.
- PubChem Fingerprint: 881 bits in length structural keys that is used by PubChem in similarity search.
Once fingerprints are generated for each molecule, they can be compared using similarity metrics, which assign a numerical value to quantify how alike two molecules are.
Similarity Metrics
The most common metric is the Tanimoto coefficient, which calculates the ratio of shared features to the total features present in both molecules. A Tanimoto score of 1 means the molecules are identical in the fingerprint representation, while a score of 0 indicates no shared features. Other metrics, such as Dice and Cosine similarity, can also be used depending on the context.
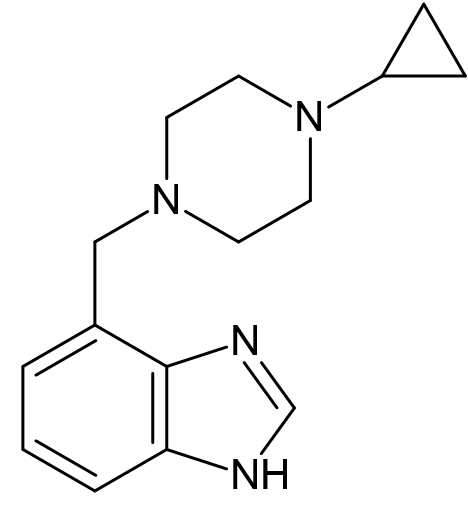
If you searched for the following structure in PubChem, you can see that there is no matching results for the structure.
If you clicked on the similarity tab on PubChem you will see the following page:
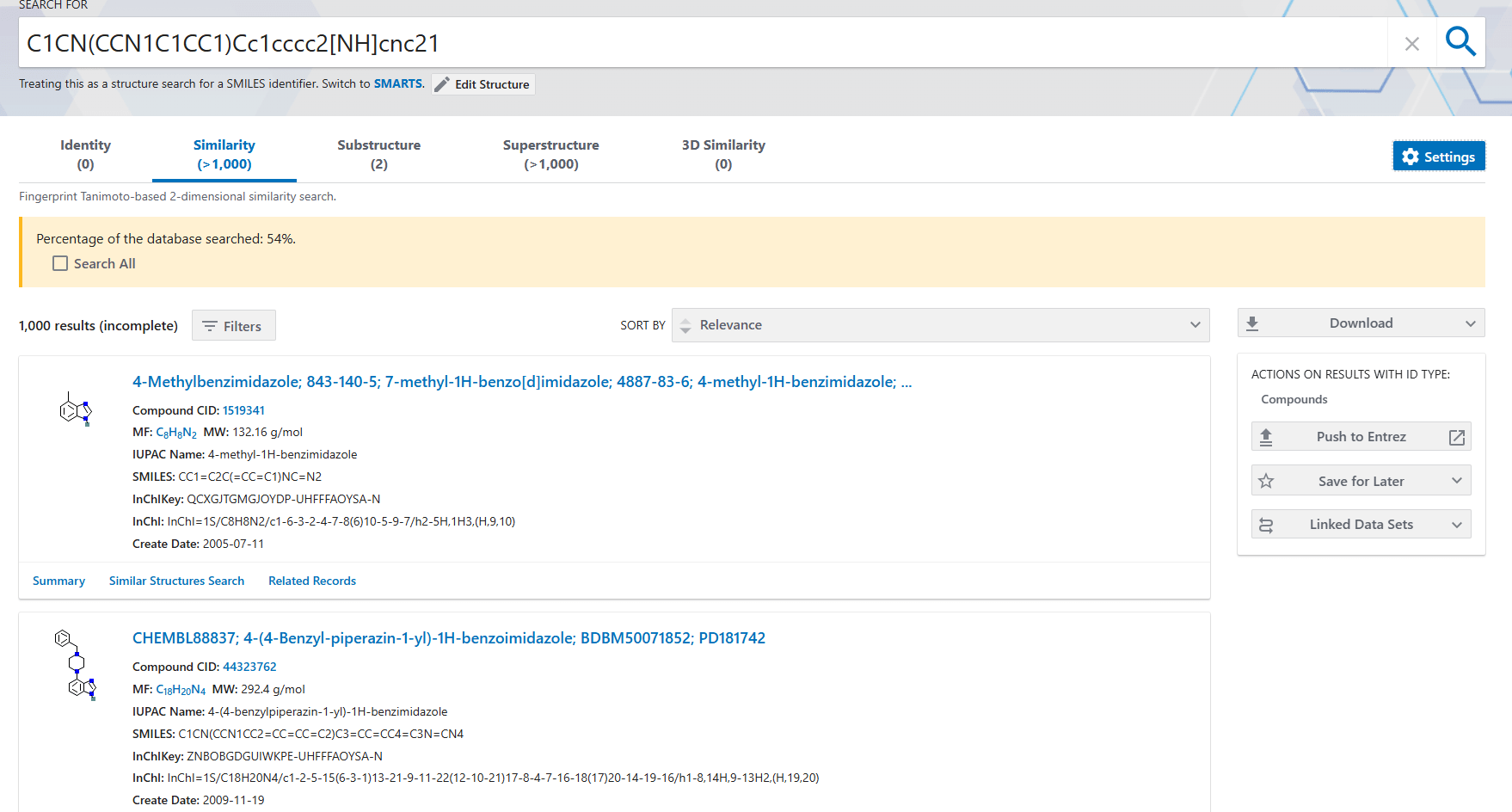
You can see structures with similar features such as the presence of the 1,3-benzodiazole or the piperazine rings.
Clustering Molecules
Once similarity scores are available, molecules can be grouped using clustering algorithms. Clustering organizes compounds into sets of similar molecules, called clusters, based on a predefined similarity threshold or algorithmic rules. Clustering helps to simplify large datasets, visualize chemical space, and guide the selection of representative compounds for further study.
Common clustering methods include k-Means Clustering, which divides molecules into a predefined number of clusters by minimizing the distance of molecules to their cluster centers.
Here is an example of how clustering can be applied. Take a look at the following image of a small library of 13 compounds. When clustered, these compounds can be separated into three distinct groups based on similar properties. These properties can be derived from fingerprints or molecular descriptors, as discussed in the QSAR chapter.
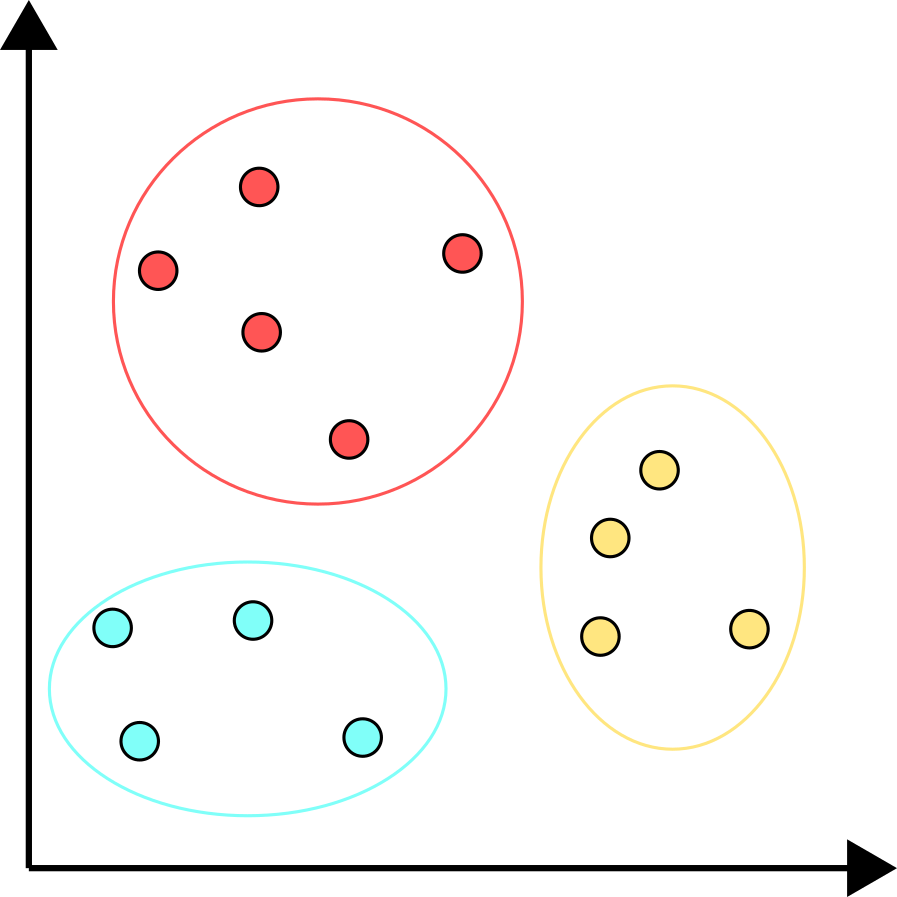
The compounds from each cluster should be similar to other compounds in the same cluster but different than compounds from the other clusters. For example, the red cluster can be polycyclic compounds, the yellow one can be amino acids that have amine and carboxylic acids in each compound, and the cyan cluster can be high molecular weight compounds.
Compounds within each cluster are more similar to one another than to compounds in other clusters. For example, the red cluster may contain polycyclic compounds, the yellow cluster may include amino acids featuring both amine and carboxylic acid groups, and the cyan cluster may consist of high molecular weight compounds. Clustering in this way helps to organize chemical libraries, reduce redundancy, and guide the selection of representative compounds for further study or experimental testing.